TFNW BYOB
TFNW BYOB
Brains not Beer
Introduction
Contributors
Topics
| BC: Before PC | AD: After Digital | |
|---|---|---|
| Turing | Layers | |
| Logic Gate | Biology | |
| Neuron | Images | |
| Learning | Time Series | |
| Automata | ||
| XOR Fail |
Advanced Topics
- Feedback/Recursion
- Optimization
- Reinforcement
- Dropout
Bonus
- NN Applications (by Zeke)
- NN Tuning (by Thunder)
History
- 1943 MCP neuron (binary logic)
- 1948 Hebbian Learning
- 1958 Rasenblatt Perceptron
- 1964 Kernel Perceptron
- 1969 XOR fail
- 1972 ELIZA vs. Parry
. . .
AI Dies
It’s Alive!
- 1970 Conway: Game of Life
- 1972 [ELIZA]https://en.wikipedia.org/wiki/ELIZA)
- 1980s Multilayer FFNN
- 1990 robotics and games
- 2000 sports (basketball)
- 2010 Deep learning
- 2012 convolutional
- 2013 hyperopt
Turing’s Universal Computer

- Logic Gates (Relays)
- Memory (Tape)
Biological Brains
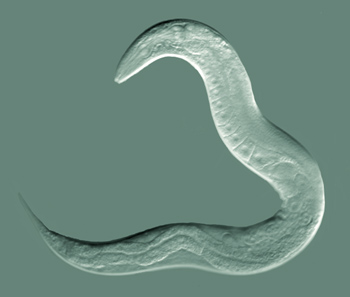
Neuroscientists simulated a whole brain
. . .
… of a nematode worm (C Elegans)
~300 neurons
~200 in central nervous system
Pretend Brains
Artificial brains aren’t at all like human brains,
. . .
or even a worm brain
Neuron simulations are broad abstractions - pulses in time not modeled - chemistry - neuron internal feedback loops
Brain? Really?
No, not really. Just pretend. In a computer.
Abstraction
- 18th century: stars modeled as crystal spheres
- Copernicus: Earth at the center

Neuron
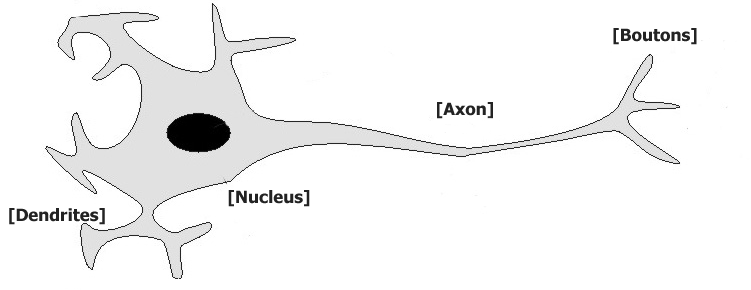
“Pretend” Neuron
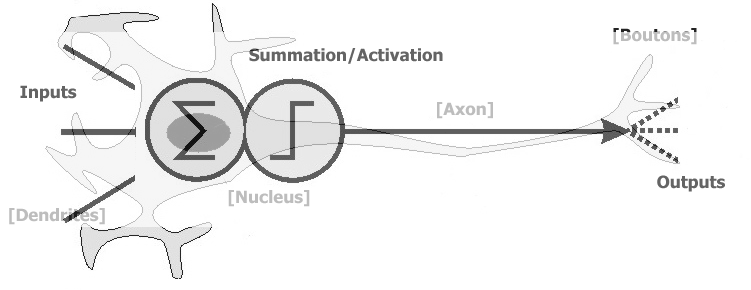
Math
- You don’t need to know Linear Algebra, just…
- multiply
- add
- check thresholds
- Equation/code is short (in python)
- 100s of neurons
- Not billions
- Train for minutes
- Not decades
Logic
McCulloch Pitts Neuron (MCP)
Modeled after biological neurons. Can be combined to perform any logical or mathematical operation.
Binary output: 0 or +1 Any Number of binary inputs Inhibitory input with “veto” power
Let’s Simulate
- raise your hand if:
- either of your neighbors raises her hand
- put your hand down:
- either if both of your neighbors are same “state”
XOR
Complexity

Game of Life

Rosenblatt’s Perceptron
Designed to be “trainable” Rosenblatt provided a training algorithm
Binary output: -1 or +1 Any number of real inputs Threshold = 0 Weights and inputs can be real-valued
Let’s Build One
iPython Notebook
Modern Neurons
Activation functions
- sigmoid
- saturation
- threshold
- linear
- sync
- tanh
Priorities Matter
- Neanderthals’ big eyes likely drove them to extinction[^*]
- Too much of a good thing
- Less room for imagination
- Less neurons for social interaction

Lesson: Depth Wins
A deeper brain may be better
than
High resolution sensing
Layers
- Many layers (6+ for)
- Many neurons/layer
- Sophisticated Connection Architectures
- fully-connected
- convolutional
- recursive
- sparse
- random
- scale-free
Neural Nets were “made” for …
Hyperdimensionality
- Images (object recognition)
- Sound (speech recognition)
- Time series (weather, finance, election prediction)
Pattern Recognition
- Prediction
- Segmentation (sound, image)
- Feature detection
- Fraud detection
- Intrusion detection
- Game cheating detection . . .
But often they can produce useful features that seemingly don’t make sense
. . .
except for images
Neural Nets help when …
You don’t know what to look for
(feature engineering)
- FFT
- DCT
- Wavelets
- PCA/SVD
- RF
- Statistics (mean, std, diff, polynomial)
- LPF/BPF/HPF
- Resampling/Interpolation/Extrapolation
And when …
Conventional control laws fail
- shooting a basketball
- kicking a soccer ball
- stabilizing an inverted pendulum
- helicopter stunts
Neural Nets can help invert “Physics” models
- Infer reflectance despite shadow/glare/haze
- 2-D image -> 3-D object
- When direct measurement of 3-D not possible
- stereoscopic vision
- structured light
- lidar
- radar
- sonar
- Kinect or RealSense
NNs “see” through structured noise
Both images and sound often suffer from
- occlusion
- obsucration/haze/fog/fade
- rotation/translation/warping
NNs need data and power
- Lots of examples to learn from
- CPU/GPU cycles to burn
- Google speech recognition doesn’t run on your phone…yet
Layers
Classification
- The most basic ML task is classification
- Predict “rain” (1) “no rain” (0) for PDX tomorrow
Supervised Learning
We have historical “examples” of rain and shine
Since we know the classification (training set)…
Supervised classification (association)
Rain, Shine, Partly-Cloudy ?
Wunderground lists several possible “conditions” or classes
If we wanted to predict them all
We would just make a binary classifier for each one
All classification problems can be reduced a binary classification
Perceptron
Sounds mysterious, like a “flux capacitor” or something…
It’s just a multiply and threshold check:
if (weights * inputs) > 0:
output = 1
else:
output = 0Perceptron
Perceptron
Linear
Time Series
Need something a little better
Works fine for “using” (activating) your NN
But for learning (backpropagation) you need it to be predictable…
Sigmoid
Again, sounds mysterious… like a transcendental function
It is a transcendental function, but the word just means
Curved, smooth like the letter “C”
What Greek letter do you think of when I say “Sigma”?
“Σ”
What Roman (English) character?
- “E”?
- “S”?
- “C”?
Sigma
You didn’t know this was a Latin/Greek class, did you…
Σ (uppercase) σ (lowercase) ς (last letter in word) c (alternatively)
Most English speakers think of an “S”
when they hear “Sigma”.
So the meaning has evolved to mean S-shaped.
Shaped like an “S”
The trainer ((backpropagator)[https://en.wikipedia.org/wiki/Backpropagation]) can predict the change in weights required
Wants to nudge the output closer to the target
target: known classification for training examples
output: predicted classification your network spits out
But just a nudge.
Don’t get greedy and push all the way to the answer Because your linear sloper predictions are wrong And there may be nonlinear interactions between the weights (multiply layers)
So set the learning rate (\alpha) to somthething less than 1 the portion of the predicted nudge you want to “dial back” to
Code
Example: Predict Rain in Portland
Visualizing a Brain[^*]
- watch the weights evolve
- activate with examples and watch intermediate layers

Get historical weather for Portland then …
- Backpropagate: train a perceptron
- Activate: predict the weather for tomorrow!
NN Advantages
- Easy
- No math!
- No tuning!
- Just plug and chug.
- General
- One model can apply to many problems
- Advanced
- They often beat all other “tuned” approaches
Disadvantage #1: Slow to Learn
- cubic to learn
- quadratic to activate
Example
- 24+ hr for complex Kaggle example on laptop
- 90x30x20x10 ~= 1M DOF
- 90 input dimensions (regressors)
- 30 nodes for hidden layer 1
- 20 nodes for hidden layer 2
- 10 output dimensions (predicted values)
Disadvantage #2: They don’t often scale (difficult to parallelize)
- Fully-connected NNs can’t be easily hyper-parallelized (GPU)
- Large matrix multiplications
- Layers depend on all elements of previous layers
Scaling Workaround
At Kaggle workshop we discussed paralleling linear algebra
Scaling Workaround Limitations
But tiles must be shared/consolidated and theirs redundancy
- Data flow: Main -> CPU -> GPU -> GPU cache (and back)
- Data com (RAM xfer) is limiting
- Data RAM size (at each stage) is limiting
- Each GPU is equivalent to 16 core node
Disadvantage #3: They overfit
- Too manu nodes = overfitting
What is the big O?
- Degrees of freedom grow with number of nodes & layers
- Each layer’s nodes connected to each previous layer’s
- That a lot of wasted “freedom”
- Many weights are randomly zeroed/ignored (Random Dropout)
O(N^2) to activate
O(N^3) to learn
Not so fast, big O…
>>> np.prod([30, 20, 10])
6000
>>> np.sum([30, 20, 10])**2
3600Rule of thumb
NOT N**2
But M * N**2
N: number of nodes M: number of layers
Automated Architecture Limits
assert(M * N**2 < len(training_set) / 10.)
I’m serious… put this into your code. I wasted a lot of time training models for Kaggle that was overfit.
Augment with your Brain
- Imprint your net with the structure of the problem
- Feature engineering
- Choose activation function
- Partition your NN
- Prune and evolve your NN
- Genetic algorithms
This is a virtuous cycle!
- More structure (no longer fully connected)
- Each independent path (segment) is parallelizable!
- Automatic tuning, pruning, evolving is all parallelizable!
- Just train each NN separately
- Check back in with Prefrontal to “compete”
Engineering
- limit connections
jargon: receptive fields
- limit weights
jargon: weight sharing
All the rage: convolutional networks
Ideas
- limit weight ranges (e.g. -1 to 1, 0 to 1, etc)
- weight “snap to grid” (snap learning)
- dream up your own activation function
- improve the back-propagation function
Resources
- keras.io: Scalable Python NNs
- Neural Network Design: Free NN Textbook!
- pug-ann: Helpers for PyBrain and Wunderground
- PyBrain2: We’re working on it
Code highlighting test
function linkify( selector ) {
if( supports3DTransforms ) {
var nodes = document.querySelectorAll( selector );
for( var i = 0, len = nodes.length; i < len; i++ ) {
var node = nodes[i];
if( !node.className ) {
node.className += ' roll';
}
}
}
}