- Who has done Data Science?
- Stats, ML, NLP?
- optimization, controls, classification, prediction
- DBs or ORMs?
postgres,mysql,neo4j,sqlite,django
- Stats, ML, NLP?
- Data Science using Python?
- R, Matlab, Octave?
- NLP (Natural Language Processing) using Python?
nltk,scrapy,numpy,collections.Counter
Data Science with `pug`
PDX-Python
January 28, 2014
Survey
Data
- Acquisition (ETL)
- Exploration (EDA)
Data Acquisition
ETL
- Extract -- download, API, scrape
- Scrapy
- Transform -- shuffle columns, normalize
- pug --
manage.py dbstats manage.py inspectdb
- pug --
- Load --
manage.py loaddata- DBA (Database Administration)
Exploration
- EDA (Exploratory Data Analysis)
- Questions to Ask
- Size (# of databases, tables, records)
- Dimensions: # columns, any natural language
- Connectedness: relationships, indexes, PKs
- Types: ordinal, continuous, discrete, bulk (NL)
Exploration
- Things to calculate
- Standard deviation, entropy
- Min/Max
- Correlation coefficients (mutual information)
scikit-learn has an excellent flow chart
Science
- Model (hypothesis)
scikithas a lot of excellent modelspughas very few
- Test
- Configure the model
- Tune
- Cross-sample validation
- repeat
- Share -- Visualization
Let's Do NLP
specifically LSI = Latent Semantic Indexing
- Count words (build an 'Occurrence Matrix
- Reduce dimensions (word vocabulary)
- Visualize the connections (graph)
- Visualize & sort the matrices
- SVD on sparse matrix <-- not shown here, but in
pug
Count Word Occurrences
from pug.nlp.classifier import get_words
docs = ['Explicit is better than implicit.',
'Simple is better than complex.',
'Flat is better than nested.',
]
O_sparse = [Counter(get_words(d)) for d in docs]
print O_sparse
[Counter({'better': 1, 'explicit': 1, 'than': 1, 'implicit': 1}),
Counter({'simple': 1, 'better': 1, 'complex': 1, 'than': 1}),
Counter({'better': 1, 'flat': 1, 'than': 1, 'nested': 1})]
Total Counts
from collections import Counter
total = Counter()
for c in O_sparse:
total += c
print total
Counter({'than': 3, 'better': 3, 'flat': 1, 'simple': 1, 'explicit': 1,
'complex': 1, 'nested': 1, 'implicit': 1})
- Not very interesting
Occurrence Matrix
from tabulate import tabulate
words, O = list(total), []
for counts in O_sparse:
O += [[0] * len(words)]
for word, count in counts.iteritems():
j = words.index(word)
O[-1][j] += count
print tabulate(O)
flat simple explicit than better complex nested implicit
---- ------ -------- ---- ------ ------- ------ --------
0 0 1 1 1 0 0 1
0 1 0 1 1 1 0 0
1 0 0 1 1 0 1 0
Graph Visualization with D3
- Our word occurrence matrix shows connections
- word1 <--0--> doc1
- word2 <--3--> doc1
- ...
- This is a directed graph
- source: word
- target: document
- value: frequency (number of occurrences)
Introducing `pug`
$ git clone git@github.com:hobsonlane/pug.git
$ cd pug/pug/miner/static
$ python server.py &
$ firefox http://localhost:8001/occurrence_force_graph.html
Do it yourself: hobson.github.io/pug
A More Interesting Example
from nltk import download, ConditionalFreqDist
download('inaugural')
from nltk.corpus import inaugural
cfd = ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target)) [1]
Frequency Distribution Over Time
`cfd.plot()`
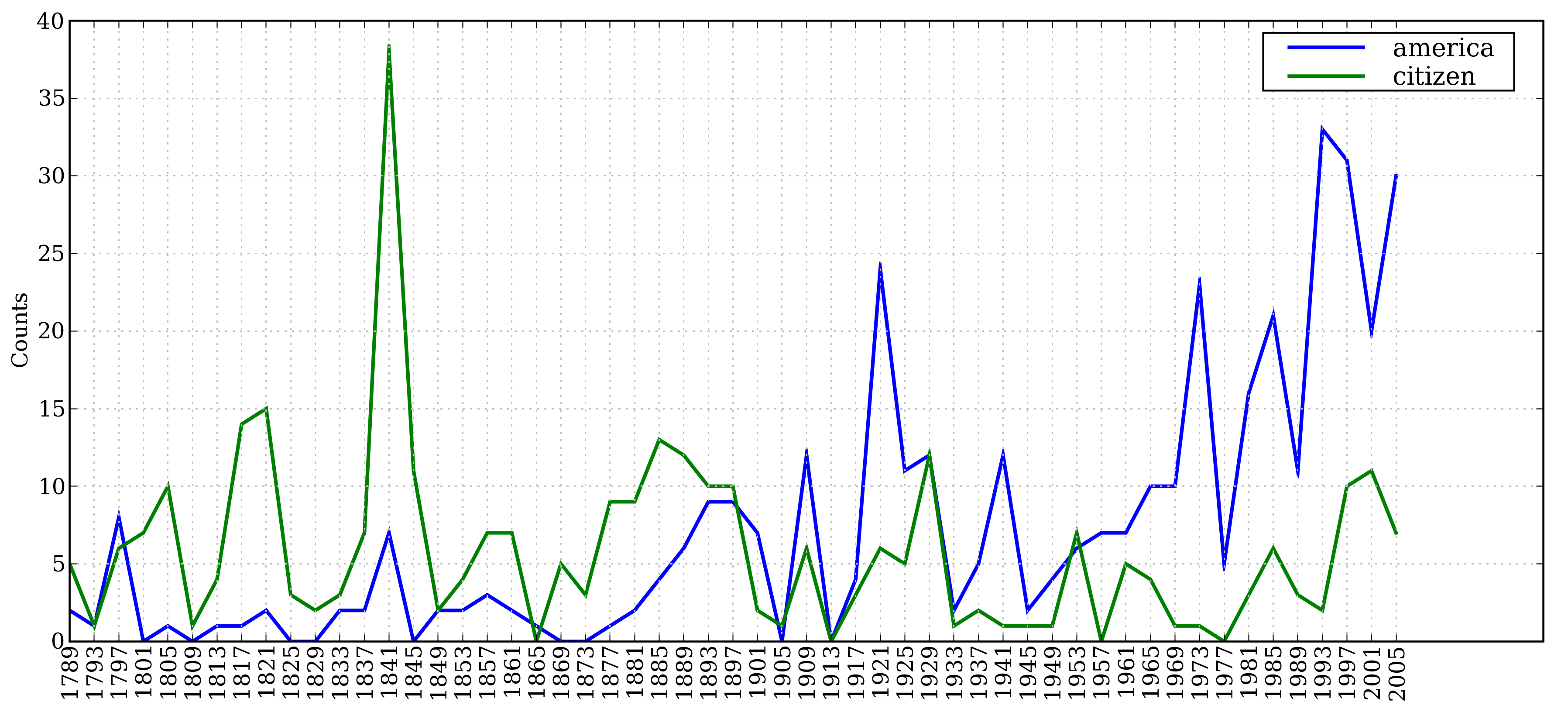
Which words are important
Entropy
$\sum_{i=0}^n P(x_i) \log_b(P(x_i))$
>>> from scipy.stats import entropy
>>> entropy([.5, .5]) * log(2.)
1.0
>>> from pug.nlp import inaugural
>>> inaugural.renyi_entropy([.5, .5], alpha=1)
1.0
What Patterns Do You See?
hobson.github.io/pug
- Outliers?
- Documents and Words
- George Washington... because of infrequent use of "the"
Curse of Dimensionality
- Difficult to untangle
- Additional pop ups and highlighting of edges would help
- Additional dimensions as size and shape of circles
- What about short-circuiting the documents to see word-word connections?
- view source
- Adjust charge, length, stiffness, friction -- balancing game...
- Stability vs Structure
- Beauty vs Complexity
Words Shared by Documents?
Multiply the frequencies a word is used in documents linked to it to get a "total" count:
Document<-->Document graph or matrix
$\mathbf O_{docs}=\mathbf O \mathbf O^T$
$\mathbf O_{words}=\mathbf O^T \mathbf O$
(for the examples given previously)
`pug` Modules
- crawler: django app for controlling wikiscrapy
- crawlnmine: django app for settings.py
- db: db_routers, explore, sqlserver
- miner: django app for db exploration
- nlp: classifier,
db_decision_tree, db, mvlr, parse, util, re, wikiscrapy format numbers & dates, importing of "pivots" in spreadsheets
Thank You for the Education
- Sharp Laboratories -- John, Jeff, Phil, LiZhong
- Building Energy -- Aleck, John, Steven
- Squishy Media -- Eric, Xian, Ben, Greg, Jesse
Resources
Contributors
- Hobson Lane pugauthors@totalgood.com
- LiZhong Zheng lizhong@MIT.edu
- Your Name Here ;) pugauthors@totalgood.com
Thanks PDX-Python!
And the open source world...